
Oumi’s Study Finds 50% of AI Overviews Untrustworthy
A not-so-simple study of SimpleQA and AI search results

Google’s AI Overviews have in a short time become an indispensable part of how we find information. So much so, in fact, that one study found visits to media sites dropped more than 50% between early 2024 and early 2026, with some outlets losing over 90% of their web traffic. Given its ubiquity and the acceptance of the public to trust its information, an important question to ask is: “Are Google AI Overviews trustworthy?”
Oumi recently performed an analysis of Google AI Overviews to answer this exact question and our findings greatly surprised us.
We found that AI Overviews were accurate approximately only 9 out of 10 times. And about half of AI Overviews contained facts not supported by the cited sources. Given Google users perform searches “googols” of times a year, this is not an inconsequential number of inaccurate and untrustworthy overviews.
Our study complements other recent work reported in the media:
[Fortune] Google’s AI overviews are 44% more likely to trash your brand than ChatGPT
[Wired] Google’s AI Overviews Can Scam You. Here’s How to Stay Safe
[The Guardian] Google AI Overviews put people at risk of harm with misleading health advice
So, how did we do this work, how did it depend on Oumi’s technology, and what does it mean for you, a David to Google’s Goliath? Read on, my gentle reader, and all shall be revealed.
Experiment
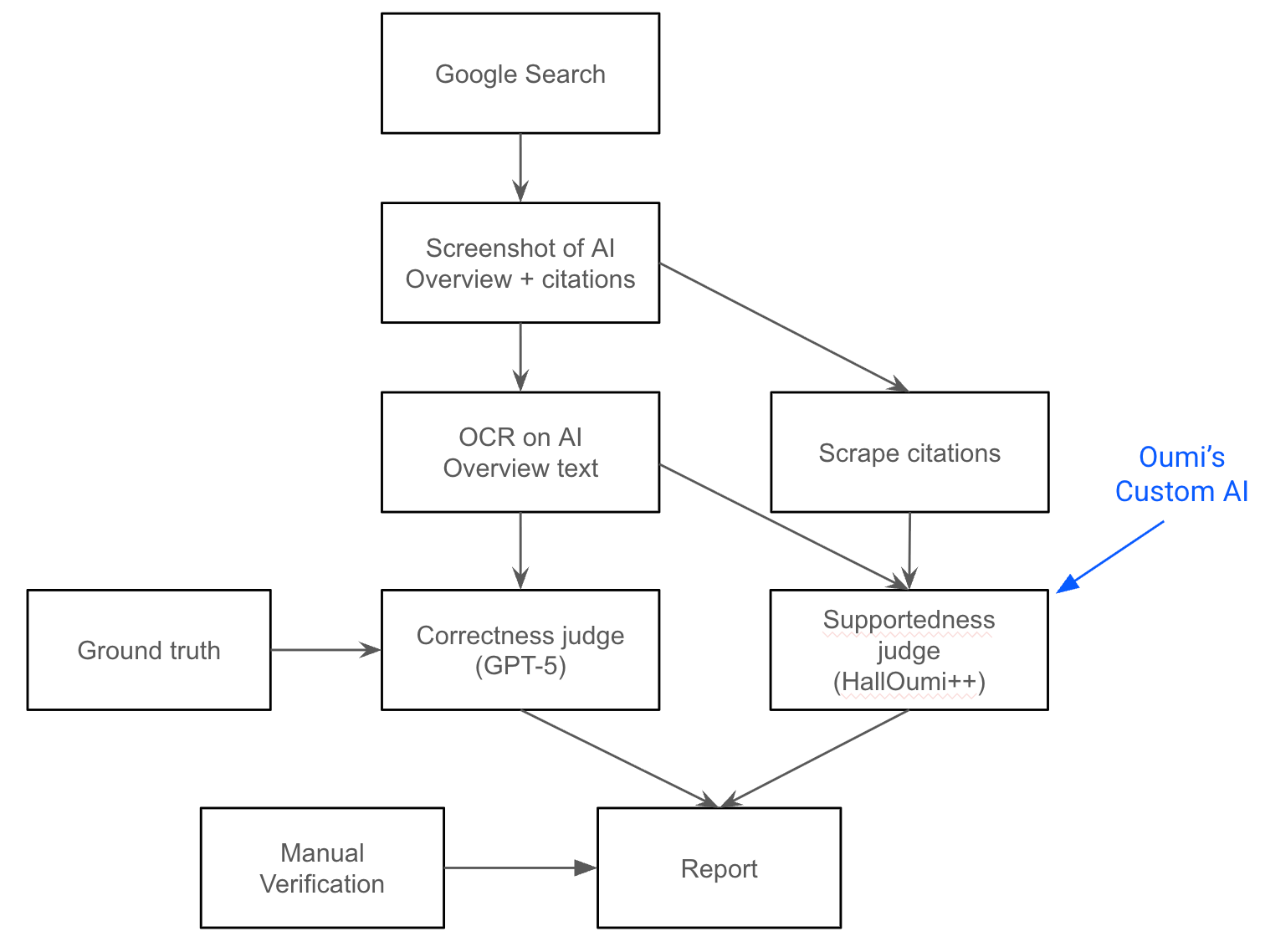
The objective of Oumi’s experiment was to answer two questions:
How accurate are AI Overviews?
How often do AI Overviews contain hallucinations?
I’ve given a schematic above for the entire pipeline, which allowed us to automate and scale up our results, important for reaching confident general conclusions.
Our experiment used the SimpleQA dataset for the search queries and corresponding correct answers. This dataset contains a bit over 4000 challenging factual queries, was constructed by OpenAI, and is widely used in AI research.
For each input query, our pipeline performed a Google Search. If the search results contained an AI Overview, the pipeline took a screenshot of the overview text and the citation links. If not, it retried the search several times. The overview screenshot was converted to text by an OCR model and the citation websites scraped, extracting the exact text fragment that the overview claimed to use.
Next, having the AI Overviews and their citations in plain text, we calculated whether the overview was correct and whether each sentence in it was supported by the cited sources. We used GPT-5 as an LLM-as-a-Judge for correctness, and Oumi’s HallOumi++ as an LLM-as-a-Judge for hallucinations (more on that later).
Aggregating the results over all queries combined with a hand-verified accuracy rate for the judges, we were able to estimate the accuracy and hallucination rates of AI Overviews with high confidence. We reran the experiment both in late 2025 and early 2026, which in addition allowed us to compare the change in metrics resulting from the model change powering overviews from Gemini 2 to Gemini 3.
Is HallOumi a type of cheese?
Yes it is, but it is also the name of a custom AI model built with Oumi’s technology that provides industry-leading hallucination detection. “Hallucination” in this context means a claim or fact in the output of a model that is not supported by the information in its input context. In addition to a detection label, HallOumi provides a detailed explanation for its decision.
Since the release of HallOumi in April, 2025, Oumi developed an advanced version, HallOumi++, not yet released to the public, with improved accuracy and a finer-grained prediction label: rather than just predicting “supported” or “unsupported” for each claim in the response, it produces additional labels like “inferred”, “embellishment”, “common knowledge”, “lie” and so on. We used HallOumi++ for this experiment.
You can build models like HallOumi yourself using Oumi’s technology! Oumi offers both a highly-adopted open source library for custom model development and an online AI agent for building models from a prompt, something we called VibeML.
The Oumi Platform’s agent is to AI model development what Claude Code, Cursor, and others are to software development. We offer free credits for new users and you can sign up without a credit card: platform.oumi.ai
Read our blog post to learn more about the HallOumi model: Introducing HallOumi: A State-of-the-Art Claim-Verification Model.
Findings
Here are three interesting findings from our work:
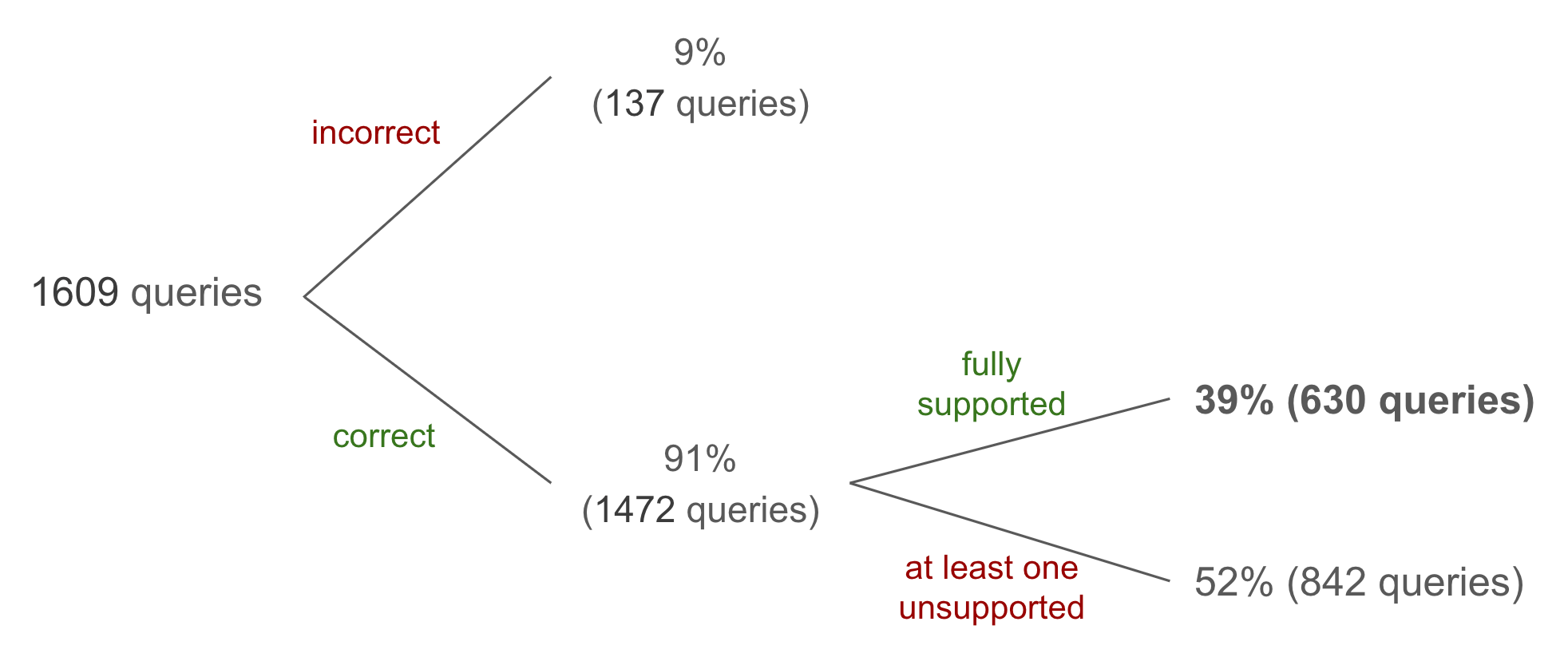
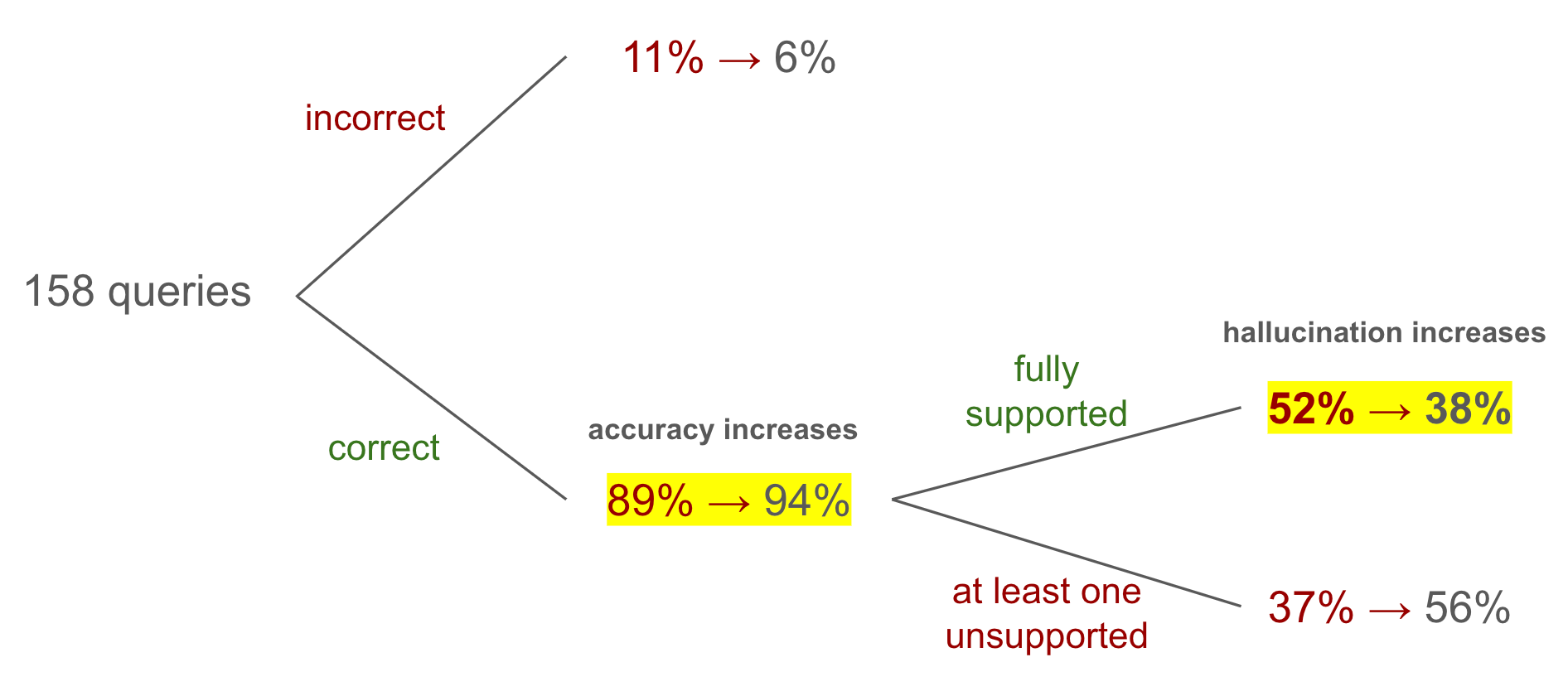
AI Overviews are fully trustworthy only 39% of the time
Of the AI Overviews powered by Gemini 3 we were able to assess, about 91% contained the correct answer. Only 39% of the total overviews were both correct and fully supported by its cited sources, a combination we term “trustworthy.”
An important distinction to make is that correctness only refers to the question asked in the query (for which we have the ground truth), and not the correctness of additional facts provided by the overview. Supportedness, or hallucination detection, is evaluated on all claims made by an overview. In the results below, “fully supported” means that every claim in the overview is supported by the cited sources.
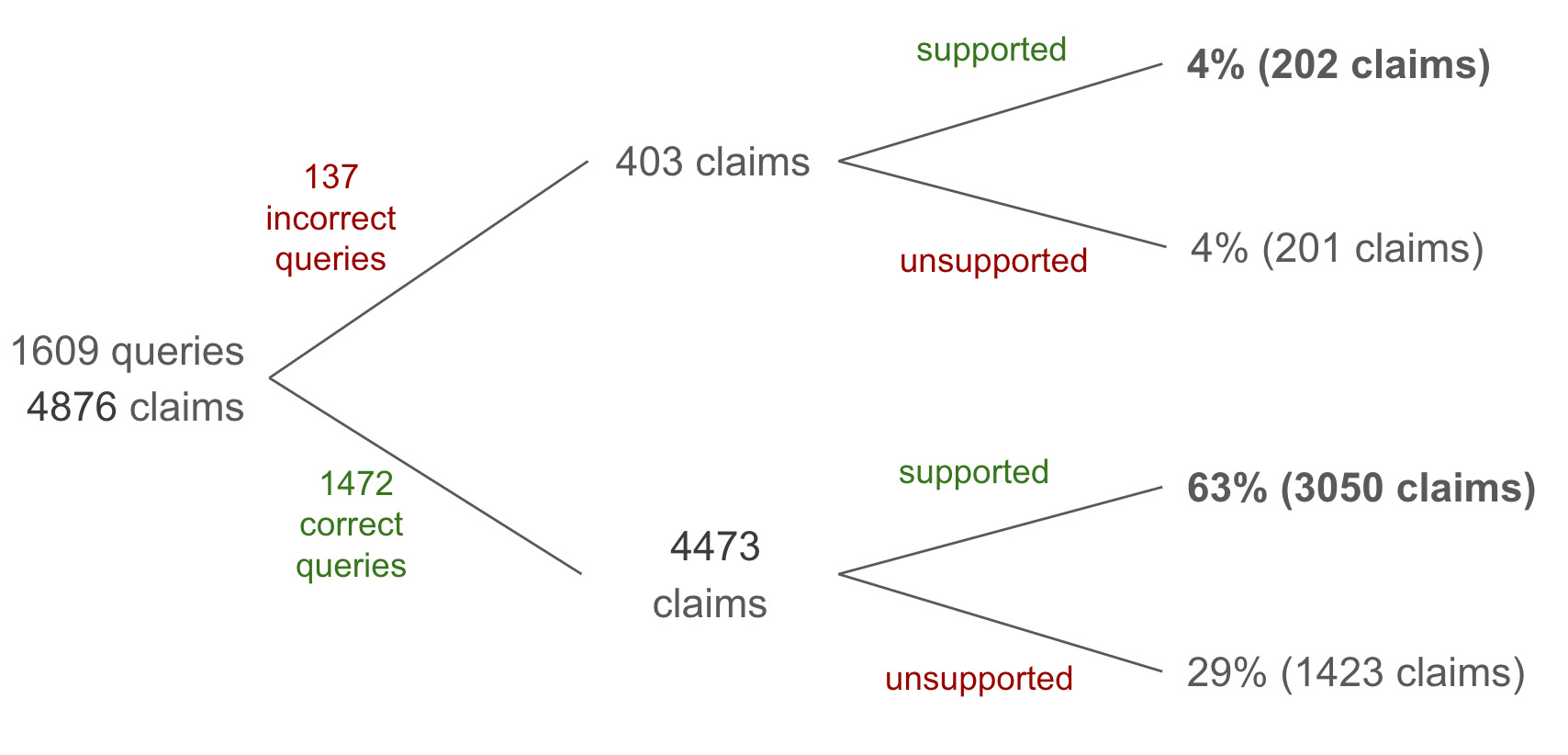
Only 67% of claims are supported by cited sources
Another way to look at these results is to aggregate on the individual claim level rather than by query. Only 67% of claims are supported by cited sources, or rather ⅓ of claims are hallucinated.
Gemini 3 is more accurate but less trustworthy than Gemini 2
It was interesting to compare Gemini 2 (late 2025) to Gemini 3 (early 2026) to see whether and how these conclusions have changed across model iterations. We compared the results on the intersection of queries for which we were able to reliably obtain overviews and citations, and found that accuracy has increased in the newer Gemini 3 based overviews. Surprisingly, we found that the rate of hallucination has also increased—others have made the observation that innovations like thinking-based models hallucinate more often and there could be a similar effect happening here.
Challenges
Data scraping
Collecting the AI Overview text and its citation text turned out to be a non-trivial task.
In collecting the AI Overview text, we used a browser automation framework to simulate a web user performing a search. Google is very sensitive to artificial traffic and so the standard framework, Playwright, triggers a bot detection screen with captcha. Fortunately, open source developers have devised a workaround: the library Patchright is a drop-in replacement for Playwright and is modified to remove any identifiable traces of detectable automation.
So, the pipeline iterated through the queries in our dataset, opened a browser with the query using Patchwright, automated pressing the button to expand the AI Overview text, capturing a screenshot of the overview, and recording the URLs to the citations. We found the most robust way to extract the overview text was to run the AI Overview screenshot through an OCR model—thankfully there are state-of-the-art open source models available on the Hugging Face Hub.
To collect the citation text, we used Patchright again to download the webpage text. Citation links on AI Overviews can be either a link to a raw HTML file, another format like PDF, or, in the most common case, a link to a specific text fragment within an HTML page. We only proceeded with analyzing the queries that had citations that were entirely fragment-based and for which we could locate the fragment text. That way, we could be sure that the context provided to our models was faithful to what Google claimed were the sources used.
When the search didn’t contain an AI Overview or when the citation page could not be accessed, the pipeline waited a minute and retried several times. In this way, we were able to perform robust data scraping.
Measuring uncertainty
A criticism we’ve read in comments to the NYT article and elsewhere is: how can an AI evaluating an AI draw valid conclusions? This is a very sensible question to ask. Judge models are LLMs, similar to the LLMs Gemini 2 and 3 powering AI Overviews, and they hallucinate and make reasoning errors just like Gemini.
There will always be uncertainty in our measurements of the world. This does not pose a problem, though, for drawing “statistically” significant or confident conclusions. If it were a problem, no reliable conclusion from a scientific experiment could be drawn, which is clearly not the case. Scientists use the language of Statistics and Probability to measure the uncertainty in our results, which allows us to draw conclusions with an acceptable level of “statistical confidence.”
Returning to our experiment, we certified the judgements of GPT-4 for accuracy and HallOumi for hallucination rate by hand for a small sample. That is, a human checked the output of our judgement models and assessed how often they were correct/incorrect. For example, on a sample of 25 accurate overviews, HallOumi made 0% false positive judgements, and about 3% false negative judgements. Using this estimate of the error rates of our models along with a statistical model, we could place the estimate of our reported results within an acceptable range with high confidence.
Moreover, using an LLM as a “judge” model is a universally accepted practice within Generative AI, including at Google. The HallOumi and HallOumi++ models were rigorously benchmarked before being put into service.
Dataset choice
A criticism made by a Google spokesperson on our findings is that SimpleQA, constructed by OpenAI, is not representative of queries that actual users would perform and that it contains errors in its ground truth answers. They responded that they prefer to use an alternative dataset called Verified-SimpleQA, constructed by Google themselves, that contains about a quarter of the same queries in SimpleQA with fact-checked answers.
According to publicly available benchmarks, by Google and others, Gemini models perform very similarly on SimpleQA and Verified-SimpleQA, being within about 3% accuracy ([Kaggle] simpleqa-verified, [Kaggle] simpleqa). Should we take it as a valid criticism that we did not evaluate Google’s product on a dataset produced by Google? We leave this to the reader to decide.
Gemini Internals
The biggest challenge posed methodologically was that we cannot know for sure exactly what context is fed into Gemini to produce each AI Overview. We assumed that the context fed to Gemini includes: the text fragments, page title, and URL for each citation source. It is possible that AI Overviews uses text on the cited sources outside of the text fragments that it claims as well as additional sources entirely not reported to the user.
Summary
Our work was carried out at the request of the New York Times who came across Oumi’s HallOumi model and realized its potential to investigate the trustworthiness of AI Overviews. Anyone can build similar models using Oumi’s technology—the Oumi Platform enables you to build a specialized SLM from just a prompt. One of the central goals of Oumi is to democratize access to AI as we believe it is crucial for the public to own and control this technology.
Further reading
HallOumi
Main article
Secondary coverage
[NDTV] Google’s AI Overviews Provide Millions Of Incorrect Results Every Hour: Report
[NYPost] Google’s AI Overviews spew millions of false answers per hour, bombshell study reveals
[The Indian Express] How accurate are Google’s AI overviews?
[Der Standard] Tests zeigen: Googles AI Overviews liegen in jedem zehnten Fall falsch
[PCMag] Google’s AI Summaries Are Regularly Lying to You, Report Finds
[Times Now] Google AI Overviews May Give Thousands Of Incorrect Answers Daily
[Ars Technica] Testing suggests Google’s AI Overviews tell millions of lies per hour
Related
[Futurism] Evidence Grows That Google’s AI Overviews Have Eviscerated the Media Industry
[Fortune] Google’s AI overviews are 44% more likely to trash your brand than ChatGPT
[Wired] Google’s AI Overviews Can Scam You. Here’s How to Stay Safe
[The Guardian] Google AI Overviews put people at risk of harm with misleading health advice
Strong results and insightful blog. Great job once again Stefan Webb!