
Small Fine-tuned Models are All You Need
But the devil is in the details—how can you get them right?


The evidence is overwhelming. Small fine-tuned models can outperform large general-purpose models like GPT-5 at tasks for which they have been specialized. And by a huge margin! Since small models require far less compute, they save on inference costs and reduce latency to users, as well.
But what exactly is the evidence? And is it all sunshine and rainbows? In this post, we’ll discuss a case-study from mid-2024 comparing the performance of small fine-tuned models to ChatGPT on a variety of real-world tasks, including:
Biomedical: Recognizing chemicals and diseases.
Natural language: Writing an apt headline for a given article.
Coding: Generating an SQL query for a given table and question.
Reasoning: Deciding whether a hypothesis follows from a given set of premises.
Mathematics: Solving high-school math problems.
Also, we’ll scrutinize why small models may not yet be used ubiquitously across GenAI development, and investigate some of the finer points of when and how our claim is true.
📊 A large-scale empirical study of fine-tuned models
Overview
But first, what exactly do we mean by a small foundation model? As always, the size is in the eye of the beholder. An informal definition, however, is that a small model is two orders-of-magnitude smaller than the largest state-of-the-art model in a given domain. For example, DeepSeek-R1 contains 671 billion parameters, so we could define a small model as having around 7 billion parameters.
In mid-2024, an applied AI research team conducted one of the first large-scale empirical studies on fine-tuning small models (Zhao et al., 2024). The researchers chose 31 tasks across a wide range of domains (see above), and fine-tuned 10 small base models on each task.
The questions being investigated included:
How does task-specific performance compare between a small base-model and its fine-tuned variant?
How does task-specific performance compare between small fine-tuned models and large general purpose ones?
Does the difference in performance between small fine-tune models and large general purpose ones vary between tasks?
Models
The small base models were versions of Llama, Mistral, Zephyr (from Hugging Face), Phi, and Gemma released prior to February 2024. They all have less than 8 billion parameters, a permission license like Apache 2.0, and can be fine-tuned on consumer-grade GPUs. For the strong model baseline, GPT-4 and GPT-3.5-Turbo were used.
Metrics
The metrics used to evaluate each task varied depending on the nature of the task. For example, the authors used accuracy for classification tasks, (1 - mean average error) for regression tasks, and a metric comparing n-grams for generation tasks. If we were to re-run this experiment today, we might wish to use LLM-as-a-Judge for the generation tasks.
Training
The method of fine-tuning used was LoRA (Low Rank-Adaption), which, at a high-level, works by freezing the base model weights and training a much smaller set of parameters expressing divergence from the base model. This contrasts with fine-tuning all weights and is a type of parameter-efficient fine-tuning.
For the more technically minded, the models were trained for 2,500 steps of batch size 16 (taking into account gradient accumulation) on a rank-8 LoRA using 4-bit precision without optimizing for the training hyperparameters. In layman’s terms, what this means is that each model could be fine-tuned on a single consumer-grade GPU card with less than 24 GB memory using the same configuration file.
Results
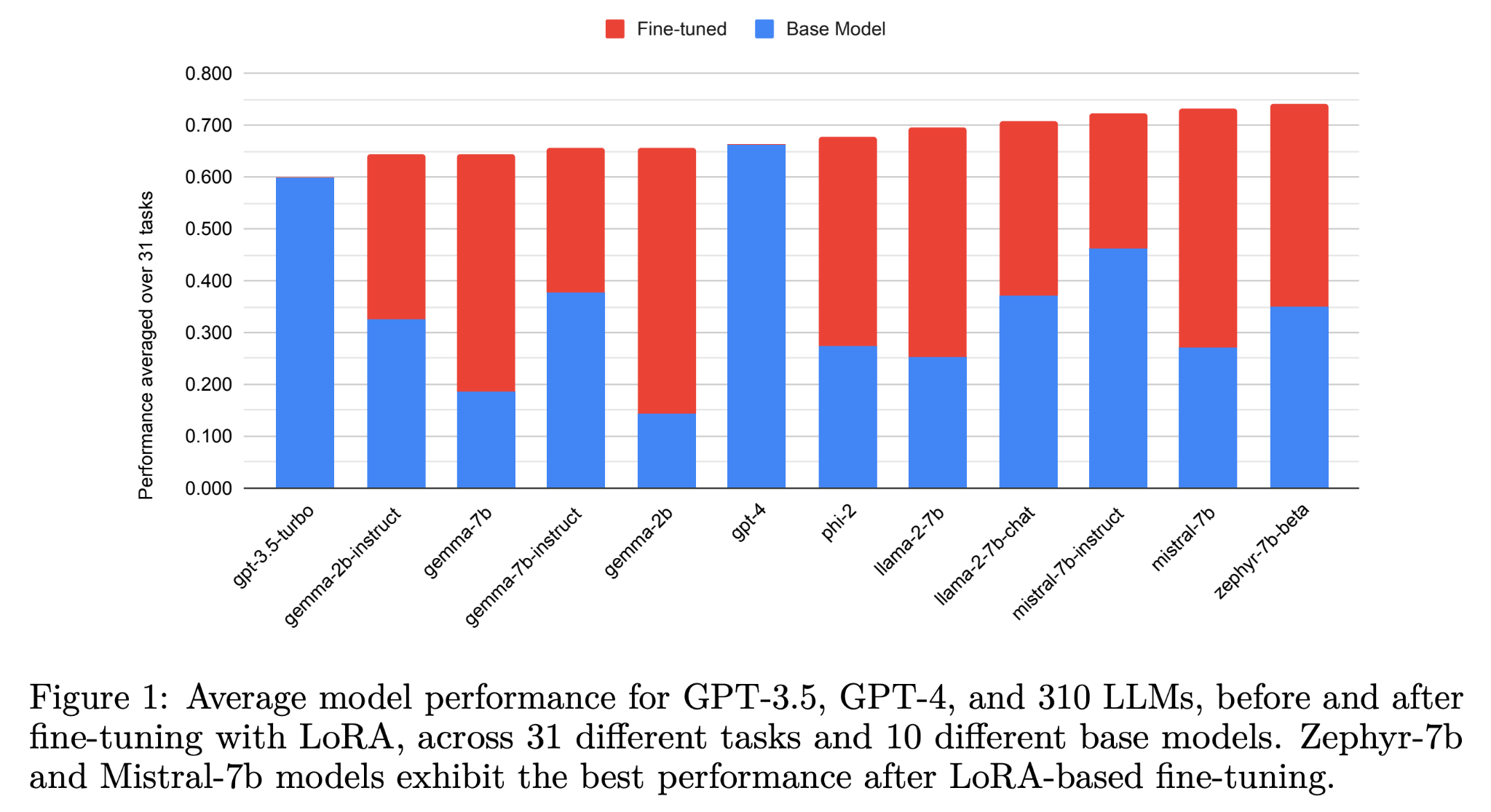
The main finding from the study (see above figure) was that, for the tasks considered, 6 of the 10 small models outperformed GPT-4 on average after fine-tuning. And all 10 smaller models outperformed GPT-3.5-Turbo. We see significant improvements from fine-tuning small base models relative to the base model (i.e., the length of the red bars).
Another interesting finding was that the improvement in performance from fine-tuning and the gap between GPT-4 and the fine-tuned model was largest for tasks in the GLUE benchmark, which are primarily traditional NLP problems. The fine-tuned models didn’t do as well when compared to GPT-4 on coding and math reasoning problems. This might not be so surprising given that the small base models capture fine-grained statistics from a large corpus of text, or rather, natural language, and these pre-February 2024 models weren’t pretrained explicitly for coding and math reasoning.
One thing to keep in mind is that there have been many advances in open-source LLMs since the release of this study. Think of the recent advancements in dealing with long context lengths, more efficiently using a model’s parameters, and training for coding and reasoning with Reinforcement Learning, to name a few. On the other hand, strong base models have gotten stronger - think GPT-5. It would be interesting to repeat this study with the resources of late-2025 and I posit that fine-tuning on more recently released base models such as Qwen3-4B-Instruct would close the gap on coding and reasoning performance.
💬 Discussion
So, why then aren’t small LLMs and VLMs ubiquitous? Why aren’t they used in the majority of GenAI applications and products built in late-2025? I’d like to put forward some hypotheses:
Extra development costs over an out-of-the-box LLM
Anecdotal reports from our industry partners have been that earlier attempts at productionizing smaller fine-tuned floundered on long and costly development cycles, especially when compared to an out-of-the-box strong LLM. This has been one of the main motivations for the development of Oumi’s Enterprise Platform, in that we solve this problem with clever automation and recent research. We can eliminate custom AI development costs so the development cycle takes mere hours, rather than months, and you can enjoy the benefits of smaller models without the downsides. We’ll elaborate in the coming weeks.
Lack of training data or misconceptions about the scale required
There may be a misconception that big data is required for successful fine-tuning or that it is too difficult to obtain training data for a custom task. In fact, as we’ll investigate in upcoming posts, a small model can be successfully fine-tuned with as little as 1000 samples, and in many cases the performance is actually better training on small, carefully curated data. Also, it is possible to synthesize data for custom tasks so this doesn’t require masses of human labor. We’ll examine both of these points in upcoming articles.
Fear of catastrophic forgetting or loss of generalization
Another common concern for fine-tuning is that the model will experience what is known as “catastrophic forgetting”, where it loses knowledge and task performance that it had prior to fine-tuning, overfitting to the new training data. This is one area where it matters to get the details right. Catastrophic forgetting is not generally a problem for parameter efficient fine-tuning methods, like LoRA, and recent research has shown how RL avoids the loss of generalization that a fine-tuned model experiences on other tasks. Similarly, we’ll go into more depth on these points in an upcoming post.
Misunderstanding about the role of fine-tuning
A common misunderstanding is that the main reason to fine-tune a model is to impart domain specific knowledge. Then—as the argument goes—you shouldn’t fine-tune because RAG (Retrieval Augmented Generation) can do this more efficiently and performantly. We agree: RAG is a much better way to bring new knowledge into your system. Where fine-tuning really shines is for teaching the model capabilities, examples of which are classification, reasoning, coding, and general tool usage.
Does this agree with your experience? Why or why not, and is there something you think I’ve missed? I welcome your comments below.
→ What’s next?
In this post, we’ve examined a single piece from the mountain of empirical evidence that small fine-tuned foundation models can outperform large general-purpose ones. They have higher task-specific performance, faster and more economical inference, to name a few. We touched upon some of the nuances in this claim and in future posts, we’ll dive deeper into the details, looking at more recent work.
Notwithstanding, a key takeaway from our discussion on why small foundation models haven’t been universally adopted is that you need to get the details right to enjoy their cost and performance benefits, and it requires technical expertise and intelligently designed infrastructure to get the details correct.
Here at Oumi, we’re specialists in the art of fine-tuning custom AI models for your application. And we do it in hours, not months.
Oumi’s platform can quickly and cheaply build a smaller fine-tuned model for your application outperforming GPT-5, and we’d love to hear from you if you’re interested; why not set up a time to chat?
We’re also providing early access to Oumi’s Enterprise Platform for select industry partners. So pick up the metaphorical phone and let’s start the non-metaphorical conversation!
As Always, Stay Hungry and Happy Hacking! 🧑💻🤖🚀
Stefan Webb, Lead Developer Relations Engineer, Oumi
The ability to match or exceed GPT-4 performance on a 7B cannot be overstated - something that also tends to help is a fine-tuned models ability to consistently produce outputs in the correct format. System instructions only do so much...
Are there any studies available in the impact of lora weights on inferencing performance, e.g. ttft or tpot?